






Rustybrick's future pagerank tool an April fool Joke - Barry agrees,
Written by power
@ 11:11 AM
permanent link on
Wednesday, December 28, 2005
| Post a Comment |
0
comments
![]()
![]()
anyone can easily guess this tool is just guessing or predicting something which is 100% inaccurate,
Finally Barry agrees this tool was developed by him as a April fool joke,
This is what he says in his blog,
"I believe I was one of the first, if not the first, to come up with the Google PageRank Prediction Tool. I launched that tool on April 1st, 2005 - yes it was April fools day. To appease the SEM community, I added a line about the tool should be used for "entertainment purposes only." How do I come up with the future PR? I pull some historical data from different places, I won't say exactly what they are, and I either increase the current PageRank value of a page and or decrease it by a percentage factor.
So is it accurate? No way! It was an April fools joke. Sometimes it is right, and often it is wrong. But I still get emails, at least once per week, asking me questions about the tool or ways to help increase people's pagerank.
There are other tools that look at your PageRank at all the Google datacenters. They are not really future pagerank tools, they check your real time pagerank at these datacenters. If a "Google Dance" or PageRank update is taking place, it will show the current pagerank at that datacenter."
https://www.seroundtable.com/archives/003021.html
So did he finally agree he is completely wrong???, Is he telling the truth I feel No,
check this thread where barry participated
Check the posting date it says 25-3-2004, But check the posting in his blog it says April 1st, 2005 which is about 1 year difference, Even if he made a mistake mentioning 2005 instead of 2004 still the thread clearly says this tool was not released on April fools day but released before that,
PLUS see the posts where Barry is defending his tool,
An extract of some of his postings,
rustybrickrustybrick
03-25-2004, 04:36 PM
I made this nifty tool that checks
your future PageRank. The recipe is a secret:Check out the new Google PageRank
Prediction Tool (http://www.rustybrick.com/pagerank-prediction.php).Let me know
if there are any bugs here. Thanks.
03-25-2004, 04:48 PM
hmm... for most its accurate. Well, your sites will probably have crazy PR values and go through the roof. You do a damn good job of getting links.;)but the value of your forum makes sense.
Replying to john's reply he says "hmm... for most its accurate. "
For Most its accurate HUH... and he didn't say its april fool joke there???? why??//
Further more"rustybrick
03-25-2004, 05:54 PM
How does it determine what sort of increase to expect? Its like telling you the recipe to Coke Cola. ;)"
Its a coke Cola secret??/
rustybrick
03-25-2004, 06:00 PM
its a long detailed formula. I have never found an example of a 0% change. Thanks for pointing that out.
Long Detailed Formula or April fool Joke??//
03-25-2004, 07:46 PM
based on the feedback, we fixed some problems.
Fixed problems with a April fool tool??/
More
rustybrick
base, ur still 0 - that's fine. Spear, i am rounding down, like google does. So its under a 5.49. Returning whole numbers. but its a good thing, u increased a bit behind the scenes.
rustybrick
some people don't, i know you do - but i got people cursing me out because its not giving them to the decimal point.
LOL some newbies are so dumb, cursing an april fool tool for not showing decimal point.
Read that thread for more Fun,
But in same thread experts like Bob Wakfer Writes,
"I don't know why this thread is still alive and why anybody is wasting time on it. The tool is a joke. There is no way it is or can be anywhere close. Google couldn't forecast your PR in a months time and there is no way this tool can. It a sham and a delusion. You are all either wasting your time, or deluding yourself, or both. There are lots of good tools out there that can help you. This is not one of them."
Well said bob,
SEO Genie.
personality-arp.org hacked by UNL0CK to notorious hacker
Written by power
@ 11:05 AM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
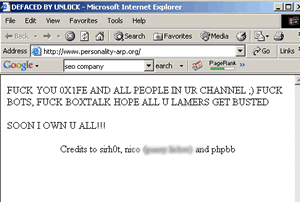
personality-arp.org an SEO tool site has been hacked by a notorious hacker, we see the following when we visit the page,
"FUCK YOU 0X1FE AND ALL PEOPLE IN UR CHANNEL ;) FUCK BOTS, FUCK BOXTALK HOPE ALL U LAMERS GET BUSTEDSOON I OWN U ALL!!!
Credits to sirh0t, nico (***** *******) and phpbb
we stared some text because it uses bad language not good for our users,
Promoting Adsense the wrong way, - SEO Site using bad tactics to make people click adsense,
Written by power
@ 10:56 AM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
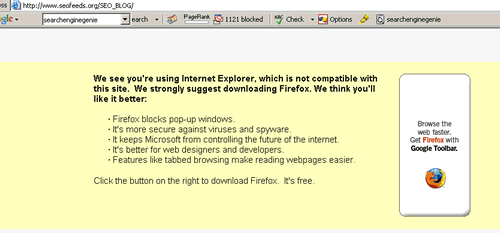
We just came across a site which was using adsense, their content triggers firefox ads , when about 90% internet users ( people using internet explorer ) they see this message
We see you're using Internet Explorer, which is not compatible with this site. We strongly suggest downloading Firefox. We think you'll like it better:
· Firefox blocks pop-up windows.
· It's more secure against viruses and spyware.
· It keeps Microsoft from controlling the future of the internet.
· It's better for web designers and developers.
· Features like tabbed browsing make reading webpages easier.
Click the button on the right to download Firefox. It's free.
webmasterworld cloaks robots.txt file for a good purpose.
Written by power
@ 10:22 AM
permanent link on
Sunday, December 18, 2005
| Post a Comment |
0
comments
![]()
![]()
I hope Everyone is aware of the recent move by webmasterworld.com to make all postings private, people can view and read their threads only after they login,
They banned all bots in their robots.txt file, This is what their robots.txt file says,
"#
# Please, we do NOT allow nonauthorized robots.
#
# http://www.webmasterworld.com/robots
# Actual robots can always be found here for: http://www.webmasterworld.com/robots2
# Old full robots.txt can be found here: http://www.webmasterworld.com/robots3
#
# Any unauthorized bot running will result in IP's being banned.
# Agent spoofing is considered a bot.
#
# Fair warning to the clueless - honey pots are - and have been - running.
# If you have been banned for bot running - please sticky an admin for a reinclusion request.
#
# http://www.searchengineworld.com/robots/
# This code found here: http://www.webmasterworld.com/robots.txt?view=rawcode
User-agent: *
Disallow: /
"
User-agent: *
Disallow: /
The above robots file syntax means no bot whether its a search engine bot or a spam bot, No bot is allowed to crawl webmasterworld.com, But it was a bit strange when Greg boser mentioned this in his blog ( http://www.webguerrilla.com/clueless/welcome-back-brett ) ,
"I was doing some test surfing this morning using a new user agent/header checking tool Dax just built. Just for fun, I loaded up WebmasterWorld with a Slurp UA. Surprisingly, I was able to navigate through the site. I was also able to surf the site as Googlebot and MSNbot.
A quick check of the robots.txt with several different UA's showed that MSN and Yahoo are now given a robots.txt that allows them to crawl. However, Google is still banned, and humans still must login in order to view content.
Apparently, it's been this way for awhile because both engines already show a dramatic increase in page counts.
MSN 57,000
Yahoo 160,000
"
We were taken totally by surprise, So how does this work, Except for cloaking you cannot do this through any other method, thought we will do a bit of research on this and tried using a user Agent spoofer to navigate their site, As greg mentioned we tried using the following Useragents,
Yahoo-Slurp
Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
Googlebot/2.1 (+https://www.google.com/bot.html)
msnbot/1.0 (+http://search.msn.com/msnbot.htm)
with all the above useragents we were able to browse webmasterworld.com peacefully,
Update to greg's post:
Googlebot is now allowed to crawl webmasterworld.com via robots.txt file cloaking, Google has about 250,000 pages now, First when webmasterworld.com didn't cloak their robots.txt file and blocked all robots, Google removed all pages of webmasterworld.com from their index, It is mostly because the robots file URL was directly submitted to the automated URL removal system in google,
Google clearly talks about that here,
"Note: If you believe your request is urgent and cannot wait until the next time Google crawls your site, use our automatic URL removal system. In order for this automated process to work, the webmaster must first create and place a robots.txt file on the site in question.
Google will continue to exclude your site or directories from successive crawls if the robots.txt file exists in the web server root. If you do not have access to the root level of your server, you may place a robots.txt file at the same level as the files you want to remove. Doing this and submitting via the automatic URL removal system will cause a temporary, 180 day removal of the directories specified in your robots.txt file from the Google index, regardless of whether you remove the robots.txt file after processing your request. (Keeping the robots.txt file at the same level would require you to return to the URL removal system every 180 days to reissue the removal.)
"
https://www.google.com/webmasters/remove.html
This is the Robots.txt file we saw using the Googlebot useragent spoofer,
GET Header sent to the bot [Googlebot/2.1 (+https://www.google.com/bot.html)]:
HTTP/1.1 200 OK
Date: Sun, 18 Dec 2005 17:35:10 GMT
Server: Apache/2.0.52
Cache-Control: max-age=0
Pragma: no-cache
X-Powered-By: BestBBS v3.395
Connection: close
Transfer-Encoding: chunked
Content-Type: text/plain
326
#
# Please, we do NOT allow nonauthorized robots.
#
# http://www.webmasterworld.com/robots
# Actual robots can always be found here for: http://www.webmasterworld.com/robots2
# Old full robots.txt can be found here: http://www.webmasterworld.com/robots3
#
# Any unauthorized bot running will result in IP's being banned.
# Agent spoofing is considered a bot.
#
# Fair warning to the clueless - honey pots are - and have been - running.
# If you have been banned for bot running - please sticky an admin for a reinclusion request.
#
# http://www.searchengineworld.com/robots/
# This code found here: http://www.webmasterworld.com/robots.txt?view=rawcode
User-agent: *
Disallow: /gfx/
Disallow: /cgi-bin/
Disallow: /QuickSand/
Disallow: /pda/
Disallow: /zForumFFFFFF/
This is the header response:
HEAD Header sent to the browser [Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)]:
HTTP/1.1 200 OK
Date: Sun, 18 Dec 2005 17:35:10 GMT
Server: Apache/2.0.52
Cache-Control: max-age=0
Pragma: no-cache
X-Powered-By: BestBBS v3.395
Connection: close
Content-Type: text/plain
URI: www.webmasterworld.com/robots.txt
Source delivered to [Googlebot/2.1 (+https://www.google.com/bot.html)]:
"
User-agent: *
Disallow: /gfx/
Disallow: /cgi-bin/
Disallow: /QuickSand/
Disallow: /pda/
Disallow: /zForumFFFFFF/
"
From the above syntax you can see that webmasterworld.com doesnt ban googlebot or other main bots from crawling their site pages, This is not new for brett before webmasterworld.com went private Googlebot had access to paid section of webmasterworld while normal users need to subscribe,
Now the question does google endorse cloaking, Cloaking is bad as defined by Search engine guidelines, Now we can see that selective cloaking for selective sites are not bad, We dont blame brett for doing it because he has reasons to disallow spam bots and very good reasons to allow nice bots,
Brett explains why he banned bots, he says
"Seeing what effect it will have on unauthorized bots. We spend 5-8hrs a week here fighting them. It is the biggest problem we have ever faced.
We have pushed the limits of page delivery, banning, ip based, agent based, and down right cloaking to avoid the rogue bots - but it is becoming an increasingly difficult problem to control.
webmasterworld.com/forum9/9593-2-10.htm
So what is brett's answer for cloaking?
A webmasterworld.com member asks
"Brett - do you cloak your robots.txt depending on IP address that requests it? "
Brett's answer:
"only for hot/honey pot purposes. "
Webmasterworld.com is one the best place in internet, great webmasters and SEOs are born there, it is pretty harsh to complain about them but truth cannot be hidden for a long time, if not us someone will blog on this already, greg ( webguerilla ) has discussed a lot of this issue,
SEO Blog team.
A good article to read on trust rank,
Written by power
@ 4:18 AM
permanent link on
Wednesday, December 14, 2005
| Post a Comment |
0
comments
![]()
![]()
http://dbpubs.stanford.edu:8090/pub/showDoc.Fulltext?lang=en&doc=2004-17&format=pdf&compression=&name=2004-17.pdf
the above article provides great insight about the new trust rank,
What is trust rank,??
Written by power
@ 4:15 AM
permanent link on
| Post a Comment |
3
comments
![]()
![]()
Here is what wikipedia says about trust rank,
"TrustRank is a new technique proposed by researchers from Stanford University and Yahoo to semi-automatically separate reputable, good pages from spam.
Many Web spam pages are only created with the intention of misleading search engines. These pages, chiefly created for commercial reasons, use various techniques to achieve higher-than-deserved rankings on the search engines' result pages. While human experts can easily identify spam, it is too expensive to manually evaluate a large number of pages. Therefore, Google first selects a small set of seed pages to be evaluated by an expert. Once the reputable seed pages are manually identified, Google uses the link structure of the web to discover other pages that are likely to be relevant and good. Google claims that they can now effectively filter out spam from a significant fraction of the web, based on a good seed set of fewer than 200 sites."
MSN offers instructions for site owners on getting their site indexed and ranked by MSN,
Written by power
@ 4:11 AM
permanent link on
| Post a Comment |
0
comments
![]()
![]()
Content guidelines for your website from MSN
"The best way to attract people to your site, and keep them coming back, is to design your pages with valuable content that your target audience is interested in.
In the visible page text, include words users might choose as search query terms to find the information on your site.
Limit all pages to a reasonable size. We recommend one topic per page. An HTML page with no pictures should be under 150 KB.
Make sure that each page is accessible by at least one static text link.
Keep the text that you want indexed outside of images. For example, if you want your company name or address to be indexed, make sure it is displayed on your page outside of a company logo.
Add a site map. This enables MSNBot to find all of your pages easily. Links embedded in menus, list boxes, and similar elements are not accessible to web crawlers unless they appear in your site map.
Googleguy Matt cutts response to selling links by jeremy
Written by power
@ 6:35 PM
permanent link on
Tuesday, December 13, 2005
| Post a Comment |
0
comments
![]()
![]()
This is what googleguy says,
"
At this point, it shouldn't be a surprise what I have to say about any particular site (Hi Jeremy!) selling links. Danny gives a good recap here, and I'm happy that Danny can channel me and say what I would say at this point. Let's see how succinctly I can say it. Many people who work on ranking at search engines think that selling links can lower the quality of links on the web. If you want to buy or sell a link purely for visitors or traffic and not for search engines, a simple method exists to do so (the nofollow attribute). Google's stance on selling links is pretty clear and we're pretty accurate at spotting them, both algorithmically and manually. Sites that sell links can lose their trust in search engines.
Okay, everyone should expect me to say those things. Let's lighten up this post a bit. Would anyone be surprised to find that some link buyers turn around and then sell links to other sites? And that those links may not be of the highest quality? Let's take a concrete example. Jeremy vetted his sponsored links trying to remove anything reminiscent of blog comment spam, but take one of Jeremy's sponsors, www.thisisouryear.com. Can you get from that site to the "Lesbian Gay Sex Positions" site at www.gay-sex-positions.com in two mouse clicks? Looks like there may be some scraped content on that porn site.
Just to be clear: it's Jeremy's site. Of course he can try any experiment he wants (YPN, AdSense, BlogAds, AdBrite, Chitika, Amazon affiliate program, selling links with nofollow, selling links without nofollow, offering flying lessons to the 10,000th visitor, selling pixels, auctioning lemurs, etc.) to make money. Many such experiments cause no problems for search engines. But if a web site does use a technique that can potentially cause issues, it's understandable that search engines will pursue algorithmic and manual approaches to keep our quality high.
I take it as progress that most people would expect what I was going to post. So, other than the two-clicks-to-scraped-lesbian-porn, how many people could have guessed everything I was going to say? "




