



Google ( Goog ) Gains more than 12% after Q1 2008 RESULTS
Google’s ( GOOG ) Q1 financial results are released and breaking everyone’s expectation Google has gained 42% profit over the first Quarterly of 2007 and has gained 7% over the last Quarter of 2007. This is much better than everyone’s expectations especially after decline in value of many company’s shares.
At this moment Google’s shares are trading around 13% increase which is a very good sign for Google.

Financial results Summary as per Google’s investor relations:
Q1 Financial Summary
Google’s results for the quarter ended March 31,
2008, include the operations of DoubleClick Inc. from the date of acquisition,
March 11, 2008, through the end of the quarter, and are compared to
pre-acquisition results of prior periods. The overall impact of DoubleClick in
the first quarter of 2008 was immaterial to revenue and only slightly dilutive
to both GAAP and non-GAAP operating income, net income and earnings per
share. Google reported revenues of $5.19 billion for the quarter ended March 31,
2008, an increase of 42% compared to the first quarter of 2007 and an increase
of 7% compared to the fourth quarter of 2007. Google reports its revenues,
consistent with GAAP, on a gross basis without deducting traffic acquisition
costs, or TAC. In the first quarter of 2008, TAC totaled $1.49 billion, or
29% of advertising revenues. Google reports operating income, net income, and
earnings per share (EPS) on a GAAP and non-GAAP basis. The non-GAAP
measures, as well as free cash flow, an alternative non-GAAP measure of
liquidity, are described below and are reconciled to the corresponding GAAP
measures in the accompanying financial tables.
GAAP operating income
for the first quarter of 2008 was $1.55 billion, or 30% of revenues. This
compares to GAAP operating income of $1.44 billion, or 30% of revenues, in the
fourth quarter of 2007. Non-GAAP operating income in the first quarter of
2008 was $1.83 billion, or 35% of revenues. This compares to non-GAAP operating
income of $1.69 billion, or 35% of revenues, in the fourth quarter of 2007.GAAP net income for the first quarter of 2008 was $1.31 billion
as compared to $1.21 billion in the fourth quarter of 2007. Non-GAAP net
income in the first quarter of 2008 was $1.54 billion, compared to $1.41 billion
in the fourth quarter of 2007.
GAAP EPS for the first quarter of 2008 was
$4.12 on 317 million diluted shares outstanding, compared to $3.79 for the
fourth quarter of 2007 on 318 million diluted shares outstanding. Non-GAAP
EPS in the first quarter of 2008 was $4.84, compared to $4.43 in the fourth
quarter of 2007.
Non-GAAP operating income, non-GAAP operating margin,
non-GAAP net income, and non-GAAP EPS are computed net of stock-based
compensation (SBC). In the first quarter of 2008, the charge related to
SBC was $281 million as compared to $245 million in the fourth quarter of
2007. Tax benefits related to SBC have also been excluded from these
non-GAAP measures. The tax benefit related to SBC was $51 million in the
first quarter of 2008 and $42 million in the fourth quarter of 2007.
Reconciliations of non-GAAP measures to GAAP operating income, operating margin,
net income, and EPS are included at the end of this release.
GOOG Financial results.
Interview with Udi Manber Google’s search quality scientist
I just read this very interesting interview from Vice president of Search Quality in Google Mr.Udi Manber,
http://www.popularmechanics.com/blogs/technology_news/4259137.html
According to wikipedia
“Udi Manber (Hebrew: אודי מנבר) is an Israeli computer scientist. He is one of the authors of agrep and GLIMPSE. As of December 2007, he is employed by Google as one of their vice-presidents of engineering.
[edit] BiographyHe earned both his bachelor’s degree in 1975 in mathematics and his master’s degree in 1978 from the Technion in Israel. At the University of Washington, he earned another master’s degree in 1981 and his Ph.D. in computer science in 1982.
He has won a Presidential Young Investigator Award in 1985, 3 best-paper awards, and the Usenix annual Software Tools User Group Award software award in 1999.
He was a professor at the University of Arizona and authored several articles while there. He wrote Introduction to Algorithms — A Creative Approach (ISBN 0-201-12037-2), a book on algorithms.
He became the chief scientist at Yahoo! in 1998.
In 2002, he joined Amazon.com, where he became “chief algorithms officer” and a vice president. He later was appointed CEO of the Amazon spin-off company A9.com. He filed a patent on behalf of Amazon.[1]
As of February 8, 2006, he has been hired by Google as one of their vice-presidents of engineering. In December 2007, he announced Knol, Google’s new project to create a knowledge repository.[2]
“
John Muller’s example of Google local search ranking
John Muller in one of his recent blog post explains how easy its to get into Google local search and how important its for business.
From the time Google’s Local Search was introduced people were eager to get into it. Some think its difficult to get into local search but the fact its not. Google sees some factors like User reviews from some popular sites as a ranking factor for local search.
From Mr. John’s example here
the No.1 ranking site treetoptoys.com has nothing but a flash homepage and some flash links if that site were to compete for Organic rankings i am sure they wont rank but for local they are doing fine because of the reviews they have on other sites.
Also John points how important its for SEO companies to find local businesses and help them out to go online and rank in local search. Its very good for their business. Just some simple traditional SEO is more than enough to rank in local search since the competition pretty low.
Read in detail on John’s view here http://johnmu.com/untitled-document/#more-117
Google ( GOOG ) to Announce First Quarter 2008 Financial Results
Google to Announce First Quarter 2008 Financial Results
MOUNTAIN VIEW, Calif. – April 7, 2008 – Google Inc. (NASDAQ:GOOG) today announced that it will hold its quarterly conference call to discuss first quarter 2008 financial results on Thursday, April 17, 2008 at 1:30 p.m. Pacific Time (4:30 p.m. Eastern Time).
The live webcast of Google’s earnings conference call can be accessed at http://investor.google.com/webcast. The webcast version of the conference call will be available through the same link following the conference call.
About Google Inc. Google’s innovative search technologies connect millions of people around the world with information every day. Founded in 1998 by Stanford Ph.D. students Larry Page and Sergey Brin, Google today is a top web property in all major global markets. Google’s targeted advertising program provides businesses of all sizes with measurable results, while enhancing the overall web experience for users. Google is headquartered in Silicon Valley with offices throughout the Americas, Europe and Asia. For more information, visit www.google.com.
The much awaited GOOG first quarter financial results are bound to be released on April 17th. This is big news due to the current status lots of companies are reporting loss of earnings. Google one of the largest company in the world need to prove that its still a very popular and profitable company. Current share price of Google is already hovering around 450$ down from 750$. If they show a less than expected earning their shares are bound to tumble much more
Lets wait and see how it goes on,
pagerank 10 link claim – fake claim in adwords advertisment

http://www.w3.org/
http://www.macromedia.com/
http://www.energy.gov/
http://www.nasa.gov/
http://www.google.com/
http://www.nsf.gov/
http://www.whitehouse.gov/
http://www.real.com/
http://www.usa.gov/index.shtml
http://www.doe.gov/
I dont think any of the above sites are willing to sell text link on their website, US government website, Department of energy, science foundation , white house, real player site, adobe all these guys done need to make money selling text links. So you figure out what these guys are upto,
Cloaking still works in Google Blog search – cloaking in Google
I was surprised to see Cloaking still works in Google or atleast in Google blog search, When I was searching today for our blog post which usually features in Google blog search as as we make an entry we came across a really weird site, It showed some snippet in search results which was very interesting to click but when we click on the site it redirects to a via-gra spam site
 This is the spammer’s website check the redirected and cloaked URL,
This is the spammer’s website check the redirected and cloaked URL,
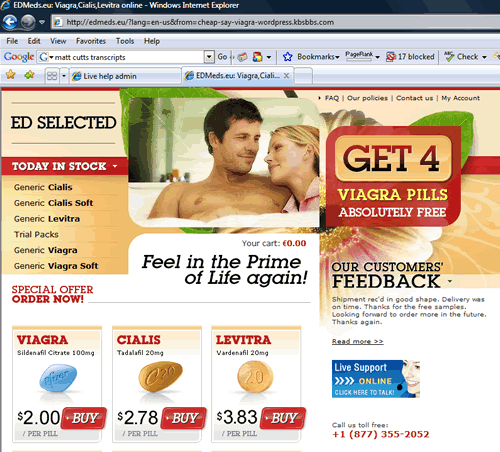
So how will Google stop spamming and cloaking in blog search
Got to wait and see,
Search Engine Genie.
How to stop my site from showing up on non-US Google results
When I was going through webmaster world Google forum I saw this weird post
How to stop my site from showing up on non-US Google results
Wow one second it took me by surprise I seriously want to checkout why someone really wants to block access to their site from non-Google results. Here is the post from that person
“First, I want to make clear, I am not worried about bringing my page rank up at
all, I just want to stop showing up on non-US google results. So this isn’t
about SEO.
I have a site serving the SE United States. However, 80% of my
visitors come from Ireland, Israel, China, Japan, Italy, South America, and of
all places, Botswana?
I used some google tool (I can’t remember which) that
showed my page rank on non US google indexes varies from 4 to as high as 7.
That would explain the off-continent percentage, because I have a white bar
/ page rank 0 here. So…
1. Is there really a different feed for different
countries?
2.Can I keep google indexing for US users but not others?
3.Is it one googlebot gathering data for all places, or are there different
ones? (That would explain why there is some google-thing on my msg boards every
day. Or there is one google bot and he lives at my place.)
4.To block them
or it, do I have to know the name of every bot and spider by IP or nickname or
whatever?
5.Is that done by htaccess or robots.txt?
“
From reading the post it looks the poster really wants to stop traffic from all countries other than Google. I don’t think this is possible since google.com results are served in almost all countries though ranking might vary.
A good response by senior member lammert was made which was very informative
“Geographic targetting boosts ranking in one region compared to others, but it
doesn’t remove a site from foreign search results. My experience is that it has
no greater power than a country TLD like .de for Germany or .fr for France, or
hosting your site on an IP address which is locate in the country to target.
1. Is there really a different feed for different countries?
No, every
Google datacenter can produce the results for all countries and languages in the
world by just changing a few parameters in the search URL. Google tries to sort
the results based on relevancy, matching languages and geographic origin of
incoming links to a site, but in principle every URL can appear in every SERP on
every visitors location. There is no such thing as totally separate feeds.
2.Can I keep google indexing for US users but not others?
3.Is it one
googlebot gathering data for all places, or are there different ones? (That
would explain why there is some google-thing on my msg boards every day. Or
there is one google bot and he lives at my place.)
There is just one
Googlebot crawling for all countries and data centers. If you are on one Google
data center, you are practically speaking in all, because they exchange pages on
the fly. There is even data sharing behind the scenes between different Google
spider technologies. If Googlebot doesn’t visit a specific URL but Mediabot
which is used for AdSense ad matching is, the pages fetched by Mediabot may be
examined and used by Googlebot.
There is no way you can block your site from
showing up in Google results for one country and not for others, unless your
site is China related and happens to trigger a filter in Google’s China
firewall.
The only way to tackle this reliably is to block the foreign
visitors at your door, i.e. use some form of geo targeting where you map the IP
address of the visitor to a geographical location and allow or deny access based
on that. But geo targeting is not 100% reliable, especially with some larger
ISPs like AOL which use a handful of proxies for all their customers and you may
end up with some foreign visitors slipping through, and worse, a number of
legitimate visitors who can’t connect anymore.
My advice is not to fight the
battle against foreign visitors, but to monetize the traffic. Many people are
fighting for traffic and you–wanting to kill 80% of your traffic because it
doesn’t match the current content of the site–are really an exception. Why not
monetize this traffic in some way instead of blocking people? This is free
traffic which is in principal targeted audience, based on that they found you
through Google search, and not some form of shady traffic generation scheme.
“
In my view there is no use blocking users from other countries they can be a valuable resource at times our site www.searchenginegenie.com gets about 50% of the traffic outside US and we really enjoy that traffic as much as the US traffic we get. Traffic from France, Germany , Spain are very useful traffic since they love Search Engines and Search Engine Optimization a lot. There are some french forums which send us traffic to our tools or blog posting, traffic is sometimes 10 times more than the traffic sent to us by active forums like searchengine watch, Digitial point forums etc. This shows their passion towards online business, Search engine optimization and the art of making money online.
Pagerank update – Is there an update going on in Google
A webmaster world member has reported pagerank change to his site. It seems his site has lost some pagerank and is now downgraded from PR5 to PR3. This looks like the New Google “Toolbar Pagerank Reduction” or TPR policy. Google introduced TPR around December 2007 to go after text link buyers and sellers. Text link advertising which passes pagerank is against Google’s policy and they introduced TPR to tackle.
Lots of sites depend on Google toolbar pagerank to judge the value of a link apart of other things like number of backlinks in yahoo and Alexa ranking. Google toolbar pagerank is a very important when it comes to buying or selling these days. A PR9 link goes for around 800$ a month which is a huge amount for a link. I am sure this industry is not flourishing anymore due to the introduction of TPR. TPR reduced text link advertising to atleast 40 to 60% I would say. It sent bubbles in link publisher’s stomach and many advertisers who were selling links for their site or buying links to their site panicked and removed all of them to make sure they don’t loose any further trust in Google.
I know being part of a SEO company that this TPR affected lot of sites that didn’t buy links but inside I appreciate Google for taking strong efforts to protect their Algorithm from being manipulated through text link advertising. I have always said Text link advertising is for the rich and famous for competitive keywords and it should stop or real quality sites that don’t buy anchor text links will not get the exposure in Google that they deserve.
Forum discussion in webmasterworld.
Googlebot now digs deeper into your forms – Great new feature from Google smart guys
Google’s crawling team has made a major step forward a step which everyone thought the Search Engine crawler will never go to. According to the Official webmaster central Blog now Google has the capability to crawl through HTML forms and find information this is a huge step forward.
Remember forms had always been a user only feature when we see a form we tend to add a query and search for products or catalogs or other relevant information. For example if we go to a product site we just see a search form, Some product sites will just have a form to reach the products on their website. There will not be any other way to access the inner product pages which might have valuable information for the crawlers. Good product descriptions which might be unique and useful for users will be hidden from t he users. Similarly imagine a edu website I personally know a lot of Edu websites which don’t provide proper access to their huge inventory of research papers, PowerPoint presentations etc.
Only way to access those papers is through a search button in Stanford website, Look at this Query you can see at least 6000 useful articles about Google which are in Stanford site. If you scan through Standford website you will not find these useful information connected to the website anywhere. They are rendered directly from a database. Now due to the advanced capability of Google bot to crawl forms they can use queries like Google research etc in sites like Standford and crawl all the PDFs, PowerPoint’s and other features that are listed there. This is just amazing and a great valuable addition.
I am personally enjoying this addition by Google. When I go to some great websites they are no where never optimized most of their high quality product pages or research papers are hidden from regular crawlers. I always thought why don’t I just email them asking to include a search engine friendly site map or some pages which has a hierarchical structure to reach inner pages. Most of the sites don’t do this nor do they care that they don’t have it. At last Google has a way to crawl the Great Hidden web that is out there. When they role out this option I am sure it will be a huge hit in future and will add few billion pages more to the useful Google index.
Also the Webmaster central blog reports Google bot has the capability to toggle between Radio buttons, drop down menus, check box etc. Wow that is so cool wish I was part of the Google team who did this research it is so interesting to make a automated crawler do all this Magic on your website which has always been part of the user option.
Good thing I noticed is they mention they do this to a select few quality sites though there are some high quality information out there we can also find a lot of Junk. I am sure the sites they crawl using this feature are mostly hand picked or if its automated then its subject to vigorous quality / Authority Scoring.
Another thing that is news to me is the capability of Google bot to scan Javascript and flash to scan inner links. I am aware that Google bot can crawl flash but not sure how much they reached with Javascript. Before couple of years Search Engines stayed away from Javascript to make sure they don’t get caught in some sort of loop which might end up in crashing the server they are trying to crawl. Now its great to hear they are scanning and crawling links in Javascript and Flash without disturbing the well-being of the site in anyway.
Seeing the positive site we do have a negative side too, There are some people who don’t want their pages hidden inside forms to be crawled by Search Engines. For that ofcourse google crawling and indexing team has a solution. They obey robots.txt, nofollow, and noindex directives and I am sure if you don’t want your pages crawled you can block Googlebot from accessing your forms.
A simply syntax like
Useragent: Googlebot
Disallow: /search.asp
Disallow: /search.asp?
will stop your search forms if your Search form name is search.asp.
Also Googlebot crawls only get Method in forms and no Post Method in forms. This is very good since many Post method forms will have sensitive information to be entered by ther users. For example many sites ask for users email IDs, user name, passwords etc. Its great that Googlebot is designed to stay away from sensitive areas like this. If they start crawling all these forms and if there is a vulnerable form out there then hackers and password thieves will start using Google to find unprotected sites. Nice to know that Google is already aware of this and is staying away from sensitive areas.
I like this particular statement where they say none of the currently indexed pages will be affected thus not disturbing current Pagerank distribution:
“The web pages we discover in our enhanced crawl do not come at the expense of
regular web pages that are already part of the crawl, so this change doesn’t
reduce PageRank for your other pages. As such it should only increase the
exposure of your site in Google. This change also does not affect the crawling,
ranking, or selection of other web pages in any significant way.”
So what next from Google they are already reaching new heights with their Search algorithms, Indexing capabilities etc. I am sure for the next 25 years there wont be any stiff Competition for Google. I sincerely appreciate Jayant Madhavan and Alon Halevy, Crawling and Indexing Team for this wonderful news.
What is the next thing I expect Googlebot :
1. Currently I dont seem them crawl large PDFs in future I expect to see great crawling of the huge but useful PDFs out there. I would expect a cache to be provided by them for those PDFs.
2. Capability to crawl Zip or Rar files and find information in it. I know some great sites which provide down loadable research papers in .zip format. Probably search engines can read what is inside a zipped file and if its useful for users can provide a snippet and make it available in Search index.
3. Special capabilities to crawl through complicated DHTML menus and Flash menus. I am sure search engines are not anywhere near to doing that. I have seen plenty of sites using DHTML menus to access their inner pages, also there are plenty of sites who use Flash menus I am sure Google will overcome these hurdles , understand the DHTML and crawl the quality pages from these sites.
Good Luck to Google From – Search Engine Genie Team,
Too much dreaming – Thanks mother to wake me up.
What a dream I had today. I slept very late to my bed after attending clients. It was a late night job and probably my body got too much heated. I had a very peculiar dream.
” I got a call from Sergey Brin founder of Google, The caller Said” Hey man we are getting too rich and lazy its too tough to run Google.com we want someone responsible to take care of our site. I feel you are the most ideal person for that, if you are Ok with it we will give you ftp and control panel access you can login and make changes as you like”
I got very excited, immediately the login details arrive first thing you know what I did logged in to the website and added our site link to the Homepage. Next day boom our server goes down due to massive traffic from Google.com” . So what next???????//
Its my mother calling for me since I overslept and its 9.00 AM. Heck had it been real, Sorry think I am blabbering too much
SEO Jeff,
Blogroll
Categories
- AI Search & SEO
- author rank
- Authority Trust
- Bing search engine
- blogger
- CDN & Caching.
- Content Strategy
- Core Web Vitals
- Experience SEO
- Fake popularity
- gbp-optimization
- Google Adsense
- Google Business Profile Optimization
- google fault
- google impact
- google Investigation
- google knowledge
- Google panda
- Google penguin
- Google Plus
- Google Search Console
- Google Search Updates
- Google webmaster tools
- google-business-profile
- google-maps-ranking
- Hummingbird algorithm
- infographics
- link building
- Local SEO
- local-seo
- Mattcutts Video Transcript
- Microsoft
- Mobile Performance Optimization
- Mobile SEO
- MSN Live Search
- Negative SEO
- On-Page SEO
- Page Speed Optimization
- pagerank
- Paid links
- Panda and penguin timeline
- Panda Update
- Panda Update #22
- Panda Update 25
- Panda update releases 2012
- Penguin Update
- Performance Optimization
- Sandbox Tool
- search engines
- SEO
- SEO Audits
- SEO Audits & Monitoring
- SEO cartoons comics
- seo predictions
- SEO Recovery & Fixes
- SEO Reporting & Analytics
- seo techniques
- SEO Tips & Strategies
- SEO tools
- SEO Trends 2013
- seo updates
- Server Optimization
- Small Business Marketing
- social bookmarking
- Social Media
- SOPA Act
- Spam
- Technical SEO
- Uncategorized
- User Experience (UX)
- Webmaster News
- website
- Website Security
- Website Speed Optimization
- Yahoo